

Com um volume massivo de dados para processar diariamente, a Amazon encontrou uma maneira inovadora de reduzir custos e melhorar a eficiência de suas operações. Ao migrar tarefas essenciais de Apache Spark para Apache Ray, a empresa obteve um ganho de desempenho de 82% e estima economizar cerca de 100 milhões de dólares por ano. A seguir, veja como essa mudança impacta a operação e os futuros projetos de dados da Amazon.
A Transição de Spark para Ray
Na conferência All Things Open 2024, o engenheiro-chefe da Amazon, Patrick Ames, explicou que a empresa buscava uma solução mais eficiente para a compactação de tabelas de banco de dados. Esta função, essencial para os serviços internos de inteligência de negócios (BI), agora é executada pelo Apache Ray, um framework Python para computação distribuída, que se mostrou significativamente mais rápido que o Apache Spark.
Apache Ray: Um Framework para Diversas Funções
Embora o Apache Ray seja amplamente usado em aprendizado de máquina, Ames destacou seu potencial como uma plataforma versátil para diferentes tarefas distribuídas. Segundo ele, o Ray oferece flexibilidade para otimizar sistemas complexos em que o uso de computação distribuída é crucial. Essa abordagem inovadora fez com que o Ray fosse uma escolha promissora para o processamento de grandes volumes de dados na Amazon.
Por Que Compactação É Essencial para a Amazon
A compactação de tabelas de dados é um processo necessário em sistemas de armazenamento que utilizam funções de “copy-on-write” ou “merge-on-read”, como os usados pela Amazon. Antes, essa tarefa era realizada pelo Apache Spark, mas a Amazon decidiu explorar o Apache Ray em busca de ganhos de desempenho.
Do Data Warehouse ao Lakehouse: A Jornada da Amazon
A migração para o Ray representa um marco na evolução das tecnologias de dados da Amazon. Desde 2016, a empresa passou de um data warehouse da Oracle para um data lakehouse em escala de exabytes, onde o armazenamento é descentralizado, permitindo maior flexibilidade e escalabilidade. Essa transição deu à Amazon maior autonomia para otimizar processos, especialmente a compactação de tabelas.
Desafios do Volume de Dados em Escala Petabyte
Em sua apresentação, Ames comentou sobre os desafios de lidar com volumes gigantescos de dados. O uso do Spark era adequado, mas quando os dados cresceram para níveis de petabytes, a Amazon precisou buscar uma alternativa que suportasse o processamento em múltiplos nós. A equipe de dados da Amazon então passou a considerar o Ray como uma solução mais eficiente.
A Adesão ao Apache Ray pela Amazon
A flexibilidade do Apache Ray atraiu a equipe de dados da Amazon. Graças à sua compatibilidade com APIs Python, o Ray possibilita a criação de pipelines para conjuntos de dados em terabytes, uma tarefa difícil para outras ferramentas como Pandas. Com o Ray, qualquer aplicação Python paralelizável pode ser distribuída em clusters de servidores de forma mais prática.
Como o Ray Otimiza o Uso de Recursos
Uma das vantagens do Apache Ray na Amazon foi a capacidade de configurar clusters de servidores de maneira otimizada. Segundo Ames, o Ray utiliza aproximadamente 55% da memória do servidor em cada cluster, com potencial para aprimorar essa utilização a 80%. Essa otimização garante que a Amazon aproveite ao máximo seus recursos computacionais.

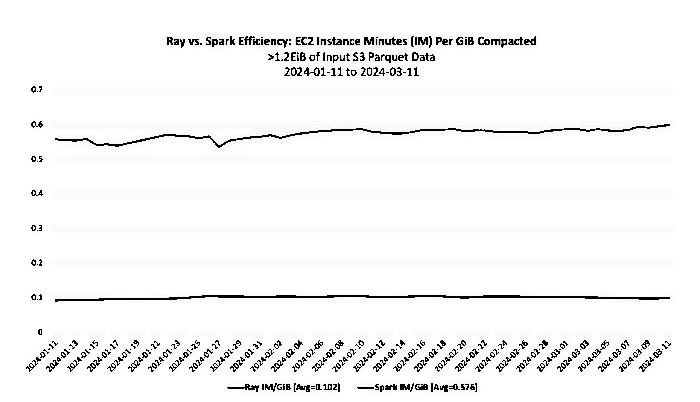
A Economia de Custos na Amazon com Ray
Com o uso do Ray, a Amazon projeta economizar cerca de 100 milhões de dólares por ano, reduzindo o tempo de uso das vCPUs em aproximadamente 250 mil anos. O impacto dessa migração é significativo, pois reduz as necessidades computacionais de forma expressiva, o que representa uma economia substancial nos custos operacionais.
O Futuro do Ray como Framework Unificado
Para Ames, o Apache Ray tem o potencial de se tornar o framework unificado de computação distribuída da Amazon, simplificando as operações de dados em toda a empresa. Com dezenas de milhares de usuários internos no data lake da Amazon, essa centralização pode otimizar processos e reduzir ainda mais os custos.
Comparação entre Spark e Ray: Desafios e Vantagens
Embora o Apache Spark ofereça funcionalidades gerais para processamento de dados, o Apache Ray apresenta vantagens em tarefas específicas, como a compactação de dados. No entanto, o Ray ainda não tem uma interface SQL simplificada, o que exige adaptações para determinados fluxos de trabalho.
Planos Futuros: Integração com Apache Iceberg
A equipe de dados da Amazon planeja adaptar o algoritmo de compactação do Ray para uso com o Apache Iceberg, com lançamento previsto para 2025. Isso deve melhorar a compatibilidade entre ferramentas como Apache Flink e Spark, facilitando a leitura e manipulação de tabelas criadas com esses frameworks.
A Versatilidade do Apache Ray
A experiência da Amazon com o Apache Ray reforça seu potencial para otimizar operações de dados em grande escala. Ames acredita que o Ray permite a criação de soluções altamente personalizadas, sendo uma excelente escolha para empresas que desejam investir em computação distribuída de alta eficiência.
Resumo para quem está com pressa
- A Amazon migrou operações de compactação de tabelas do Apache Spark para o Apache Ray, aumentando a eficiência em 82%.
- A mudança deve economizar cerca de 100 milhões de dólares por ano em custos de computação.
- Apache Ray é um framework versátil para computação distribuída, além do uso comum em aprendizado de máquina.
- A tecnologia também otimiza o uso de memória e recursos em clusters de servidores da Amazon.
- A equipe planeja integrar o algoritmo do Ray ao Apache Iceberg para mais flexibilidade em 2025.
- O Ray pode se tornar o framework principal da Amazon para pipelines de dados internos.